Evaluating Small Language Models as Summarizers for Local RAG System
We built an evaluation framework specifically for assessing how well small language models perform as summarizers in RAG systems


TL;DR
We built an evaluation framework (RED-flow) to assess small language models (SLMs) as summarizers in RAG systems
We created a 6,000-sample testing dataset (RED6k) across 10 domains for the evaluation
Cogito-v1-preview-llama-3b and BitNet-b1.58-2b-4t top our benchmark as best open-source models for summarization in RAG applications
All tested SLMs struggle to recognize when the retrieved context is insufficient to answer a question and to respond with a meaningful clarification question.
Our testing dataset and evaluation workflow are fully open source
Summarizers in Local RAG Systems
In RAG systems, summarizers transform retrieved information into coherent answers for users. This component—typically a language model—takes the user's question and relevant document chunks as input, and through carefully designed prompts, produces responses that are both accurate and helpful.
Local RAG deployments provide key advantages in privacy, cost, and reliability. Think of sensitive work documents that can't be sent to cloud LLM providers. These systems typically use SLMs as summarizers to function effectively on resource-constrained hardware.
When Small Models Face Big Challenges
Our experience in building local RAG system with SLMs reveals several key limitations that make evaluation particularly important:
Answer Completeness: Limited attention and processing capacity can cause SLMs to generate incomplete answers, addressing only parts of multi-faceted questions.
Uncertainty Handling: When context is not sufficient to fully answer a question, SLMs frequently oscillate between overconfidence and refusal, rarely expressing appropriate uncertainty or offering helpful clarification questions.
Context Adherence: SLMs may fail to ground their responses in the provided context, sometimes defaulting to pre-trained knowledge, especially in the absence of sufficient context. This can lead to hallucinations or outdated information in the final responses.
Attention Allocation: SLMs struggle to prioritize the most relevant parts of the retrieved context, leading to responses that may feel tangential or misaligned with the question.
Instruction Following: Complex prompts with multiple constraints receive inconsistent adherence, leading to responses that miss key requirements.
How do we effectively measure whether an SLM is good at summarization in a RAG system?
We know simple metrics aren't enough—we need a multidimensional evaluation framework that assesses query understanding, context utilization, response quality, and uncertainty handling.
The Quest for Better Evaluation
Evaluating summarization quality has always been challenging. Traditional metrics like ROUGE and BLEU primarily measure lexical overlap rather than semantic accuracy or usefulness.
Consider a typical evaluation using ROUGE scores: an SLM summary might use different terminology than the reference text while conveying the same information, resulting in an artificially low score. Conversely, a summary could repeat phrases from the reference while missing key concepts, earning an undeservedly high score. These metrics simply don't capture what matters most in RAG outputs.
Automated evaluation is essential for developing better SLMs. Manual human evaluation, while comprehensive, is time-consuming and expensive. This creates a bottleneck for the rapid iteration needed to improve these models.
LLMs as Expert Evaluators
After exploring various evaluation approaches, we found that Large Language Models make exceptionally effective judges for SLM outputs. Here's why:
They understand nuance like humans do. LLM judges evaluate core messages and effectiveness rather than just checking for specific words or phrases.
They process context and intent together. LLMs understand both available information and question intent, assessing appropriate context utilization.
They balance multiple dimensions. LLMs simultaneously evaluate accuracy, relevance, coherence, and uncertainty handling like human evaluators.
They scale where humans can't. LLMs evaluate thousands of examples consistently without fatigue at a fraction of human evaluation costs.
They speak the language of improvement. Beyond scores, LLMs provide detailed feedback identifying specific weaknesses needing attention.
In our early exploration, we found strong correlation between LLM judge assessments and human evaluations—often exceeding 90% agreement on quality rankings. This confirmed our intuition that LLMs could serve as reliable proxies for human judgment while offering the scalability we needed for rapid development cycles.
Limitations of Existing Frameworks
While LLM-as-judge approaches look promising, current frameworks have several key limitations:
Lack of RAG-Summarization-Specific Design: Most off-the-shelf LLM-as-a-judge frameworks are not tailored for RAG scenarios. As a result, they often include irrelevant metrics while overlooking key dimensions critical to retrieval-grounded generation. A key example is that these frameworks don't directly measure context adherence, which is essential for preventing hallucinations in RAG systems.
One-Size-Fits-All Criteria: Evaluation criteria are typically uniform across all question types. However, for questions with insufficient context, a good response should be judged by its ability to generate helpful clarifying questions—not just factual accuracy or fluency. This standardized approach fails to recognize the different requirements for different query scenarios.
Metric Entanglement: Current evaluation frameworks try to measure multiple qualities at once using the same prompt. Imagine asking someone to grade an essay on spelling, facts, and writing style all with one score—the results get mixed together! This mixing creates artificially correlated scores between different metrics that should be measuring distinct aspects of quality.
Limitations of RAG-Specific Frameworks: Even frameworks designed specifically for RAG have significant blind spots. RAGAS breaks responses into individual statements and evaluates each in isolation, missing crucial context. This leads to misleading scores where a response containing individually accurate statements might still be holistically incorrect—like correctly mentioning risk factors and a study separately, but falsely connecting them.
These limitations led us to develop a more specialized evaluation for SLMs as summarizers in RAG systems.
Building a Better Judge for RAG
Two-Stage Judge Model
An effective judge must adapt its evaluation based on context sufficiency. When the retrieved context provides enough information to answer the question, the judge should assess the response for factual accuracy and completeness. However, if the context is insufficient, the judge should assess whether the model correctly identifies this limitation and whether it attempts to ask a meaningful clarification question.
Unlike frameworks such as RAGAS that automatically penalize "I don't know" responses with a score of 0, our system recognizes that refusing to answer can be the correct behavior. This is particularly crucial for local RAG systems for these reasons:
SLMs have more limited knowledge and lower recall accuracy compared to LLMs. Compact models are inherently more prone to knowledge gaps and need robust mechanisms to acknowledge their limitations.
Local deployments typically cannot leverage external search tools to supplement missing information. When faced with incomplete context, the system must recognize these constraints rather than hallucinate answers.
Users rarely craft perfect queries. They ask ambiguous, incomplete, or overly broad questions that require clarification. A robust system needs to recognize these situations and guide users with appropriate follow-up questions.
To support this, we implemented a two-stage evaluation process:
In stage 1, the judge determines whether the context is sufficient to answer the question.
In stage 2, based on answerability, the judge evaluates the SLM's response using appropriate criteria. For answerable questions, we assess content metrics; for unanswerable ones, we evaluate refusal metrics.
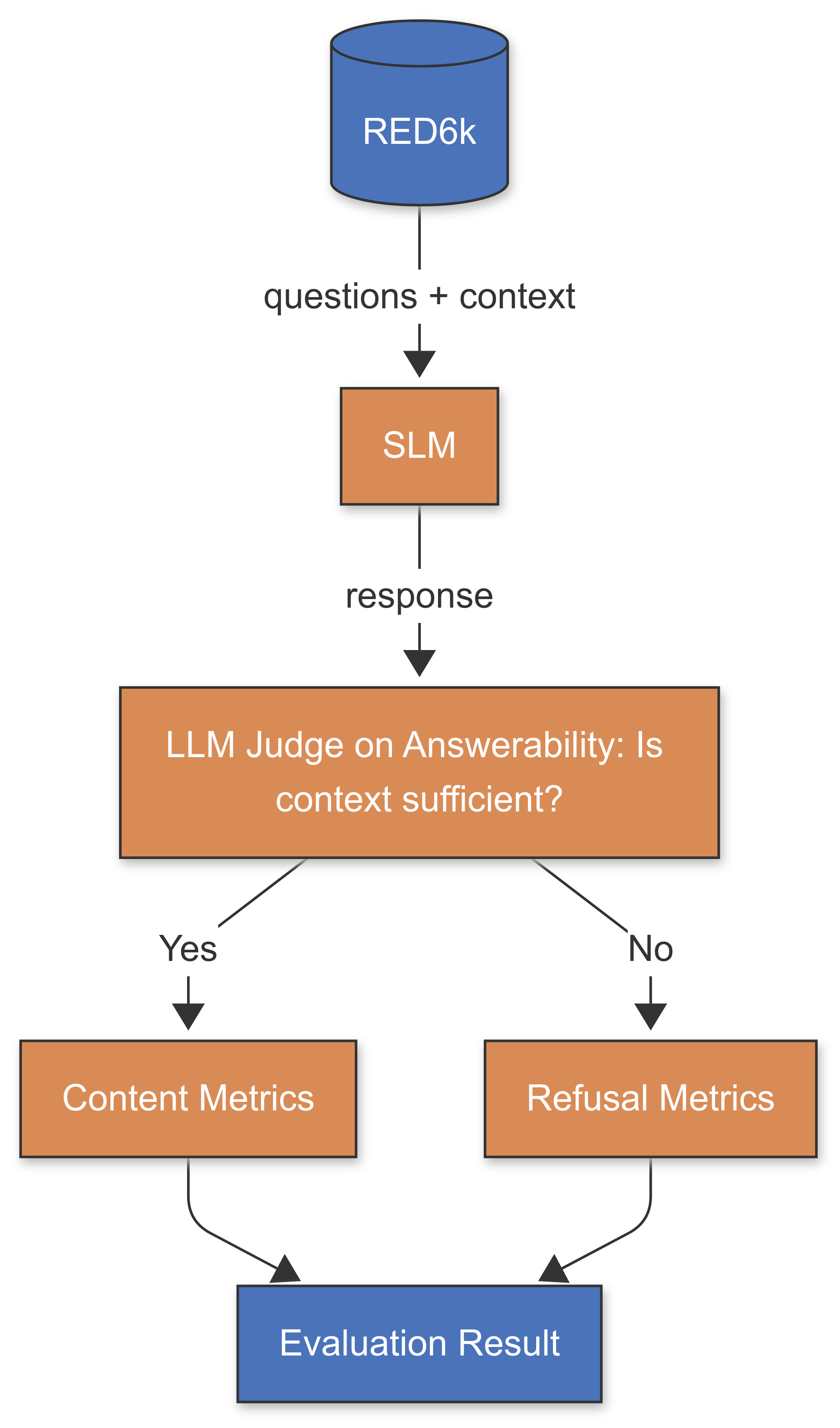
Crucially, these stages must be executed separately. We found that if the judge is exposed to the SLM’s response while determining answerability, its judgment becomes biased—even with explicit instructions to ignore the answer. This bias can reduce answerability classification accuracy from 98% to 60%.
Disentangled Metric Judging
A robust evaluation framework should assess each quality metric independently. We observed that many existing frameworks suffer from high inter-metric correlations, which reduce their diagnostic value. By evaluating each metric using separate parallel prompts, we significantly reduced these correlations and achieved results that more closely align with human judgments.
After extensive testing, we selected GPT-4o as our primary judge model due to its strong performance with minimal prompt tuning. While GPT-4.1 family models showed promise, they required more elaborate prompt engineering. We are actively evaluating whether they can serve as a viable replacement in future iterations of our evaluation pipeline.
Custom Evaluation Dataset
To properly evaluate SLMs in RAG scenarios, we curated a dataset (RED6k) of approximately 6,000 samples across 10 domains, with emphasis on manuals and policy documents. Each sample contains a user question, retrieved context chunks, and metadata tags for difficulty and answerability.
The dataset focuses on two critical capabilities for RAG summarizers:
Accurately answering questions when sufficient information is available
Appropriately refusing to answer when information is insufficient
To create challenging test cases, we simulated real-world information gaps by excluding top-3 retrieval results for some questions, instead using passages from positions 4-10 that appear relevant but lack crucial information. We also included intentionally ambiguous or overly broad questions designed to test whether models appropriately request clarification rather than attempting direct answers.
We classified questions by difficulty level (easy/medium/hard) based on reasoning complexity—from simple fact extraction to connecting information across contexts to complex reasoning requiring synthesis of multiple perspectives. The answerability tag (true/false) serves as ground truth for whether the provided context contains sufficient information to answer the question properly.
These metadata tags allow us to separate the dataset for different testing scenarios, enabling more fine-grained insights into specific strengths and weaknesses of SLMs as summarizers.
RAG-Summarization-Specific Metrics
Our evaluation framework uses eight carefully selected metrics that directly target the key capabilities of SLMs in RAG systems:
Content Metrics (if context is sufficient)
Query Relevance: Measures how well the information in the response relates to the query, regardless of answer quality
Query Completeness: Evaluates how thoroughly the response answers all aspects of the query
Context Adherence: Assesses whether the response uses information exclusively from the provided context, avoiding hallucinations
Context Completeness: Measures how much of the relevant context information is incorporated into the response
Response Coherence: Evaluates the overall readability, grammar, and structure of the response
Response Length: Judges whether the length is appropriate for the information needed
Refusal Metrics (if context is insufficient)
Refusal Quality: Evaluates how well the model explains its inability to answer when information is insufficient
Refusal Clarification Quality: Assesses how helpful the clarification questions are when refusing to answer
For each metric, our LLM judge provides not just numerical scores but detailed explanations. This transparency helps pinpoint specific strengths and weaknesses in SLM outputs. The metrics are also evaluated separately rather than simultaneously.
The distinction between "relevance" and "completeness" (similar to precision vs. recall) is important because they measure different qualities – whether the output is focused on the query versus how thoroughly it answers the query. In practice, responses sometimes fully answer the query but also include irrelevant information, scoring high on completeness but low on relevance.
The selection of these specific metrics represents deliberate trade-offs balancing evaluation depth with practical considerations of cost and time. Our current metrics doesn't specifically test for context window limitations, attention allocation efficiency, prompt sensitivity, or multi-step reasoning capabilities – areas that could be explored in future evaluation modes.
Benchmarking Popular SLMs
We ran our evaluation pipeline with two groups (by model sizes) of popular open source language models from the local LM community:
Larger Models (3-4B parameters):
Cogito-v1-preview-llama-3b
Gemma-3-4b-it
Phi-4-mini-instruct
Llama-3.2-3b-instruct
Qwen2.5-3b-instruct
Smaller Models (1-2B parameters):
BitNet-b1.58-2b-4t
Llama-3.2-1b-instruct
Gemma-2-2b-it
Gemma-3-1b-it
SmolLM2-1.7b-instruct
Qwen2.5-1.5b-instruct
Experimental Setup
We randomly pulled 1000 samples from our RED6k testing dataset with varying task difficulties (easy, medium, hard). We also observed the unanswerable samples from the data is around 10%. All models were presented with identical query-context pairs and evaluated using the same prompting template to ensure fair comparison.
For generation settings, we configured all models to use deterministic generation (do_sample=False) for consistency—with one exception. BitNet-b1.58-2b-4t was left on default settings due to bugs if done otherwise.
For the Cogito model specifically, we conducted the evaluation without the reasoning mode turned on. We also put BitNet-b1.58-2b-4t (2.4B) into the smaller group because of its actual model footprint.
Cogito and BitNet Top the Content Metrics

The content metrics reveal Cogito as the clear leader across all categories, setting the benchmark for RAG summarization quality. Perhaps most surprising is BitNet's outstanding performance despite its smaller size—it delivers exceptional results in Response Coherence and other content areas, frequently outperforming models with significantly more parameters.
Context Adherence is the strongest metric for all models, showing they can effectively stay grounded in provided information. Query Completeness scores are consistently lower, revealing that addressing multi-faceted questions remains difficult for SLMs.
Struggles with Refusal Metrics Are Universal

All models struggle significantly with refusal metrics compared to content generation. Even the strongest performers show a dramatic drop in capability when handling uncertain or unanswerable questions. Cogito achieves the best balance, with solid performance in both Refusal Quality and Refusal Clarification Quality, though still way below its content generation capabilities.
Llama-3.2-1b stands out with surprisingly better Refusal Clarification Quality for its compact size, outperforming several larger models despite its below-average absolute score. BitNet is outstanding in content generation but struggling significantly with refusal scenarios. This suggests that effective uncertainty handling stems from specific design choices rather than overall model quality or size.
Practical Implications
Our findings reveal clear recommendations for selecting RAG summarizers across different use cases:
Best Overall Model: Cogito-v1-preview-llama-3b demonstrates the strongest overall performance as a RAG summarizer.
Best for Limited Resources: BitNet-b1.58-2b-4t offers exceptional content quality with lower computational demands, making it ideal for resource-constrained environments.
Best for Uncertainty Handling: Cogito-v1-preview-llama-3b is the clear choice for applications where proper uncertainty handling is critical, with substantially better refusal metrics than any other model we evaluated.
Most Balanced: Phi-4-mini-instruct and Llama-3.2-1b provide the most consistent performance across both content and refusal scenarios, offering good trade-offs when neither content quality nor refusal handling can be compromised. While Cogito offers superior performance overall, our tests show it requires significantly more computational resources to run, making these balanced alternatives attractive for many deployment scenarios.
What's Next
Enhancing Evaluation Pipeline
We're adding several improvements to make our LLM-as-judge evaluation even more informative:
Few-shot learning examples: Adding concrete examples to our prompts and metrics to better evaluate nuanced performance aspects.
Context utilization tracking: Building tools to see exactly which parts of the context models actually use when generating responses – giving us a more complete RAG debugging toolkit.
Reasoning models as judges: Using more powerful models like O3 as judges specifically for determining query answerability, improving evaluation accuracy in ambiguous cases.
Prompt adherence metrics: Adding ways to tell whether a model fails because it can't understand instructions or because it makes poor judgments despite following instructions.
More complex reasoning tests: Expanding beyond simple QA to include multi-hop questions requiring synthesis across multiple context sections.
Expanding Dataset Diversity
We're also building more diverse evaluation datasets that better reflect real-world challenges:
Multiple languages: Testing models beyond just English to identify capabilities and gaps in other languages.
Varied document types: Adding FAQs, technical documents, narrative text, and other formats with unique summarization challenges (tables and multi-paragraph contexts).
New Models Coming Soon
Based on what we've learned, we're building specialized models to address the limitations we've found:
RAG-optimized model: Coming in the next few weeks, this model targets the specific weaknesses we identified in current open-source options.
Advanced reasoning model: We're training a model with stronger reasoning capabilities for RAG applications using RLHF to better balance refusal, information synthesis, and intention understanding.
We'll continue updating our benchmarks, dataset, and models as we learn more. Our ultimate goal is to develop a comprehensive local RAG framework that incorporates advanced techniques to mitigate common retrieval and summarization challenges, while maintaining high efficiency on resource-constrained devices—bringing cloud-quality experiences to local RAG systems that actually work.
For enterprise clients, we offer a comprehensive suite covering everything from data curation and fine-tuning to evaluation and deployment. We're already partnering with Fortune Global 500 companies to deliver efficient and secure local RAG solutions. To learn more, reach out to us at info@aizip.ai.
Resource
RED-flow - Code and notebook for the evaluation framework
RED6k - 6000 testing samples across 10 domains
_____
Blog from Aizip language model team:
Oliver Dong, Ji Guo, Haoguang (Kai) Cai, Matthew Kymn, Jinho Shin, Weier Wan